Quelle:
https://berthub.eu/articles/posts/reverse-engineering-source-code-of-the-biontech-pfizer-vaccine/
Der BNT162b-mRNA-Impfstoff besteht aus digitalem Code.
Er ist 4284 Zeichen lang und passt daher nicht in einen einzigenTweet bei Twitter.
Zu Beginn des Impfstoff Herstellungsprozesses hat jemand diesen Code auf einen DNA-Drucker hochgeladen (ja), der dann die Bytes auf der Festplatte in tatsächliche DNA-Moleküle umwandelte.

Aus einer solchen Maschine kommen winzige Mengen an DNA, die nach viel biologischer und chemischer Verarbeitung als RNA (dazu später mehr) in die Impfstoff Flasche gelangen.
Eine Dosis von 30 Mikrogramm enthält tatsächlich 30 Mikrogramm RNA.
Darüber hinaus gibt es ein durchdachtes Lipid (Fett) -Verpackungs System, das die mRNA in unsere Zellen bringt.
RNA ist die RAM Version der DNA.
DNA können Sie sich als auf einem Flash-Laufwerk gespeicherte Biologie vorstellen.
DNA ist sehr langlebig, intern redundant und sehr zuverlässig.
Ähnlich wie Computer den Code nicht direkt von einem Flash-Laufwerk ausführen, sondern aus dem RAM ,wird der Code, zunächst auf ein schnelleres, vielseitigeres aber weitaus anfälligeres System kopiert.
Was für den Computer RAM ist, ist für Biologie RNA.
Die Ähnlichkeit ist auffällig.
Im Gegensatz zum Flash-Speicher verflüchtigt sich der Arbeitsspeicher sehr schnell, wenn er nicht erhalten wird.
Der Grund, warum der Pfizer / BioNTech-mRNA-Impfstoff besonders tief gefroren gelagert werden muss, ist der Gleiche:
RNA ist wie eine zerbrechliche Blume.
Jedes RNA-Zeichen wiegt in der Größenordnung von 0,53 · 10⁻²¹ Gramm, was bedeutet, dass eine einzelne Impfstoff Dosis von 30 Mikrogramm 6 · 10¹⁶ Zeichen enthält.
In Bytes ausgedrückt sind dies ungefähr 25 Petabyte.
Allerdings werden dabei die selben 4284 Zeichen ungefähr 2000 Milliarden mal wiederholt.
Der tatsächliche Informationsgehalt des Impfstoffs beträgt etwas mehr als ein Kilobyte.
SARS-CoV-2 selbst ist rund 7,5 Kilobyte gross.
Kurz ein paar Hintergrund Informationen
DNA ist ein digitaler Code.
Im Gegensatz zu Computern, die 0 und 1 verwenden, verwendet das Leben A, C, G und U / T .
(die „Nukleotide“, „Nukleoside“ oder „Basen“).
In Computern speichern wir die 0 und 1 als Ladung oder eben keine Ladung.
Wobei in Quanten Computern, das fliessend abläuft. Als magnetischen Übergang oder als Spannung oder als Modulation eines Signals oder als Änderung der Reflexivität.
Kurz gesagt, die 0 und 1 sind keine abstrakten Konzepte – sie leben als Elektronen und in vielen anderen physikalischen Ausführungsformen.
In der Natur sind A, C, G und U / T Moleküle, die als Ketten in DNA (oder RNA) gespeichert sind.
In Computern gruppieren wir 8 Bits zu einem Byte, und das Byte ist die typische Dateneinheit, die verarbeitet wird.
Die Natur gruppiert 3 Nukleotide zu einem Codon, und dieses Codon ist die typische Verarbeitungseinheit. Ein Codon enthält 6 Informationsbits (2 * 3).
Bisher ziemlich digital. Besuchen Sie im Zweifelsfall das WHO-Dokument mit dem digitalen Code, um sich selbst davon zu überzeugen.
https://mednet-communities.net/inn/db/media/docs/11889.doc
Weitere Informationen finden Sie hier.
(„Was ist das Leben?“)
https://berthub.eu/articles/posts/what-is-life/
Könnte dazu beitragen, den Rest dieser Seite zu verstehen.
Oder wenn Sie Video mögen, habe ich zwei Stunden für Sie.
https://berthub.eu/dna
Was macht dieser Code?
Die Idee eines Impfstoffs ist es, unserem Immunsystem beizubringen, wie man einen Krankheitserreger bekämpft, ohne dass wir tatsächlich krank werden.
In der Vergangenheit wurde dies durch Injektion eines geschwächten oder unfähigen (abgeschwächten) Virus sowie eines „Adjuvans“ erreicht, um unser Immunsystem in Aktion zu versetzen.
Dies war eine ausgesprochen analoge Technik, an der Milliarden von Eiern (oder Insekten) beteiligt waren.
Es erforderte auch viel Glück und viel Zeit.
Manchmal wurde auch ein anderes (nicht verwandtes) Virus verwendet.
Ein mRNA-Impfstoff erreicht dasselbe („unser Immunsystem erziehen“), jedoch auf laserähnliche Weise.
Und das meine ich in beiden Sinnen – sehr eng, aber auch sehr kraftvoll.
So funktioniert es also.
Die Injektion enthält flüchtiges genetisches Material, das das berühmte SARS-CoV-2-Spike-Protein beschreibt.
Durch intelligente chemische Mittel gelingt es dem Impfstoff, dieses genetische Material in einige unserer Zellen zu bringen.
Diese beginnen dann mit der Produktion von SARS-CoV-2-Spike-Proteinen in ausreichend großen Mengen, so dass unser Immunsystem in Aktion tritt.
Konfrontiert mit Spike-Proteinen und verdächtigen Anzeichen dafür, dass Zellen übernommen wurden, entwickelt unser Immunsystem eine starke Reaktion gegen mehrere Aspekte des Spike-Proteins UND des Produktionsprozesses.
Und das bringt uns zu dem 95% effizienten Impfstoff.
Der Quellcode!
Beginnen wir ganz am Anfang, ein sehr guter Anfang.
Das WHO-Dokument enthält dieses hilfreiche Bild:
https://berthub.eu/articles/vaccine-toc.png
Dies ist eine Art Inhaltsverzeichnis.
Wir beginnen mit der “Kappe”, die als kleiner Hut dargestellt wird.
Ähnlich wie Sie Computer Codes nicht einfach in eine Datei auf einem Computer einfügen und ausführen können, benötigt das biologische Betriebssystem Header, Linker und Dinge wie Aufrufkonventionen.
Der Code des Impfstoffs beginnt mit den folgenden zwei Nukleotiden:
GA
Dies kann sehr gut mit jeder ausführbaren DOS- und Windows-Datei verglichen werden, die mit MZ beginnt, oder mit UNIX-Skripten, die mit #! Beginnen.
Sowohl in Lebens- als auch in Betriebssystemen werden diese beiden Zeichen in keiner Weise ausgeführt.
Aber sie müssen da sein, weil sonst nichts passiert.
Die mRNA-Kappe hat eine Reihe von Funktionen. Zum einen markiert es Code als aus dem Kern stammend. In unserem Fall stammt unser Code natürlich aus der Impfung.
Aber wir brauchen das der Zelle nicht zu sagen. Die Kappe lässt unseren Code echt aussehen, was ihn vor Zerstörung schützt.
Die anfänglichen zwei GA-Nukleotide unterscheiden sich auch chemisch geringfügig vom Rest der RNA. In diesem Sinne hat der GA einige Out-of-Band-Signale.
Die “untranslatierte Fünf-Prime-Region”
Etwas Fachsprache.
RNA-Moleküle können nur in eine Richtung gelesen werden.
Verwirrenderweise wird der Teil, in dem das Lesen beginnt, als 5 “oder” 5-Prime ” bezeichnet. Der Messwert stoppt am 3-Zoll- oder Drei-Prime-Ende.
Das Leben besteht aus Proteinen (oder Dingen, die von Proteinen hergestellt werden). Und diese Proteine sind in RNA beschrieben. Wenn RNA in Proteine umgewandelt wird, spricht man von Translation.
Hier haben wir die 5′-untranslatierte Region (‘UTR’), so dass dieses Bit nicht im Protein landet:
GAAΨAAACΨAGΨAΨΨCΨΨCΨGGΨCCCCACAGACΨCAGAGAGAACCCGCCACC
Hier begegnen wir unserer ersten Überraschung.
Die normalen RNA-Zeichen sind A, C, G und U.
U wird in der DNA auch als “T” bezeichnet.
Aber hier finden wir ein Ψ, was ist los?
Dies ist einer der außergewöhnlich cleveren Tricks des Impfstoffs.
Unser Körper verfügt über ein leistungsstarkes Antivirensystem („das Original“).
Aus diesem Grund sind die Körperzellen von fremder RNA sehr wenig angetan
und bemühen sich, sie zu zerstören, bevor sie etwas anrichten können.
Dies ist ein Problem für unseren Impfstoff – er muss sich an unserem Immunsystem vorbei mogeln.
In vielen Jahren des Experimentierens wurde festgestellt, dass unser Immunsystem das Interesse verliert, wenn das U in der RNA durch ein leicht modifiziertes Molekül ersetzt wird. – Echt jetzt.
Im BioNTech / Pfizer-Impfstoff wurde jedes U durch 1-methyl-3’-pseudouridylyl ersetzt, das mit Ψ bezeichnet ist.
Das wirklich Erstaunliche ist, dass dieser Austausch, obwohl er unser Immunsystem täuscht (beruhigt), von relevanten Teilen der Zelle als normales U akzeptiert wird.
In der Computer Sicherheit kennen Hacker diesen Trick auch – manchmal ist es möglich, eine leicht beschädigte Version einer Nachricht zu übertragen, die Firewalls und Sicherheitslösungen verwirrt, aber von den Backend-Servern weiterhin akzeptiert wird – und die dann gehackt werden können.
Wie bei anderen wissenschaftlichen Grundlagenforschungen, von denen wir jetzt profitieren, mussten die Entdecker dieser Technik darum kämpfen, ihre Arbeit finanzieren zu können, bis sie endlich allgemeine Anerkennung fand.
Wir sollten alle dafür sehr dankbar sein, und ich bin sicher, dass die Nobelpreise zu gegebener Zeit eintreffen werden.
Ok, zurück zur 5′-UTR. Was machen diese 51 Zeichen?
Wie alles in der Natur hat fast nichts eine klare Funktion.
Wenn unsere Zellen RNA in Proteine umwandeln müssen, geschieht dies mit einer Maschine namens Ribosom.
Das Ribosom ist wie ein 3D-Drucker für Proteine.
Es nimmt einen RNA-Strang auf und gibt daraufhin eine Reihe von Aminosäuren aus, die sich dann zu einem Protein falten.
Quelle: Wikipedia-Benutzer Bensaccount
https://berthub.eu/articles/protein-short.mp4
Dies ist, was wir oben sehen. Das schwarze Band unten ist RNA. Das Band, das im grünen Bit erscheint, ist das Protein, das gebildet wird. Die Dinge, die rein und raus fliegen, sind Aminosäuren plus Adapter, damit sie auf RNA passen.
Dieses Ribosom muss physisch auf dem RNA-Strang sitzen, damit es funktioniert. Sobald es sitzt, kann es beginnen, Proteine basierend auf weiterer RNA zu bilden, die es aufnimmt. Daraus können Sie sich vorstellen, dass es die Teile, auf denen es zuerst landet, noch nicht lesen kann.
Dies ist nur eine der Funktionen der UTR: die Ribosomenlandezone.
Die UTR bietet “Lead-In”.
Darüber hinaus enthält die UTR auch Metadaten: Wann sollte die Übersetzung erfolgen? Und wie viel?
Für den Impfstoff nahmen sie die aktuellste UTR, die sie finden konnten, aus dem Alpha-Globin-Gen.
Es ist bekannt, dass dieses Gen viele Proteine robust produziert.
In früheren Jahren hatten Wissenschaftler bereits Wege gefunden, diese UTR noch weiter zu optimieren (laut WHO-Dokument), so dass dies nicht ganz die Alpha-Globin-UTR ist. Es ist besser.
Das S-Glykoprotein-Signalpeptid
Wie bereits erwähnt, besteht das Ziel des Impfstoffs darin, die Zelle dazu zu bringen, reichliche Mengen des Spike-Proteins von SARS-CoV-2 zu produzieren.
Bis zu diesem Zeitpunkt sind wir im Quellcode des Impfstoffs hauptsächlich auf Metadaten und “Calling Convention” -Stücke gestoßen. Aber jetzt betreten wir das eigentliche Gebiet der viralen Proteine.
Wir haben jedoch noch eine Ebene mit Metadaten vor uns.
Sobald das Ribosom (aus der Animation oben) ein Protein hergestellt hat, muss dieses Protein noch irgendwohin gehen.
Dies ist im „S-Glykoprotein-Signalpeptid (Extended Leader Sequence)“ kodiert.
Der Weg, dies zu sehen, ist, dass sich am Anfang des Proteins eine Art Adressetikett befindet, das als Teil des Proteins selbst codiert ist. In diesem speziellen Fall sagt das Signalpeptid, dass dieses Protein die Zelle über das „endoplasmatische Retikulum“ verlassen sollte. Sogar Star Treck Slang ist nicht so geil, wie das hier!
Das “Signalpeptid” ist nicht sehr lang, aber wenn wir uns den Code ansehen, gibt es Unterschiede zwischen der viralen und der Impfstoff-RNA:
(Beachten Sie, dass ich zu Vergleichszwecken die modifizierte Modifikation Ψ durch eine reguläre RNA U ersetzt habe.)
3 3 3 3 3 3 3 3 3 3 3 3 3 3 3 3 Virus: AUG UUU GUU UUU CUU GUU UUA UUG CCA CUA GUC UCU AGU CAG UGU GUU Vaccine: AUG UUC GUG UUC CUG GUG CUG CUG CCU CUG GUG UCC AGC CAG UGU GUU ! ! ! ! ! ! ! ! ! ! ! ! !
Also, was ist los?
Ich habe die RNA nicht versehentlich in Gruppen von 3 Buchstaben aufgelistet.
Drei RNA-Zeichen bilden ein Codon. Und jedes Codon kodiert für eine bestimmte Aminosäure.
Das Signalpeptid im Impfstoff besteht aus genau den gleichen Aminosäuren wie im Virus selbst.
Wie kommt es, dass die RNA anders ist?
Es gibt 4³ = 64 verschiedene Codons, da es 4 RNA-Zeichen gibt, und es gibt drei davon in einem Codon. Es gibt jedoch nur 20 verschiedene Aminosäuren. Dies bedeutet, dass mehrere Codons für dieselbe Aminosäure codieren.
Das Leben verwendet die folgende nahezu universelle Tabelle zur Abbildung von RNA-Codons auf Aminosäuren:
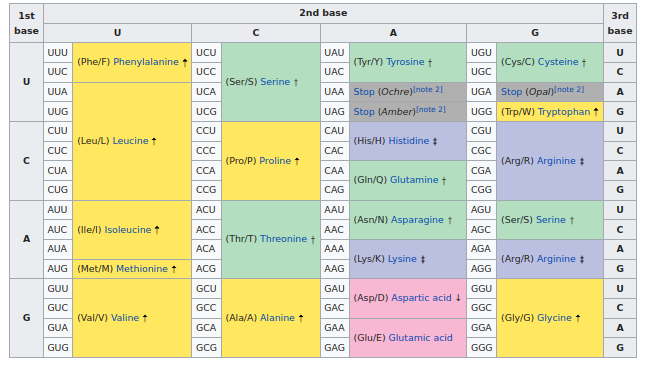
In dieser Tabelle können wir sehen, dass die Modifikationen im Impfstoff (UUU -> UUC) alle synonym sind. Der Impfstoff-RNA-Code ist unterschiedlich, aber es kommen die gleichen Aminosäuren und das gleiche Protein heraus.
Wenn wir genau hinschauen, sehen wir, dass die meisten Änderungen an der dritten Codonposition stattfinden, die mit einer „3“ oben gekennzeichnet ist. Und wenn wir die universelle Codontabelle überprüfen, sehen wir, dass diese dritte Position tatsächlich oft keine Rolle spielt, für welche Aminosäure produziert wird.
Die Änderungen sind also synonym, aber warum sind sie dann da? Bei genauerem Hinsehen sehen wir, dass alle Änderungen bis auf eine zu mehr C und G führen.
Warum sollten Sie das tun? Wie oben erwähnt, sieht unser Immunsystem die „exogene“ RNA, den RNA-Code, der von außerhalb der Zelle kommt, sehr schlecht. Um dem Nachweis zu entgehen, wurde das „U“ in der RNA bereits durch ein Ψ ersetzt.
Es stellt sich jedoch heraus, dass RNA mit einer höheren Menge an Gs und Cs auch effizienter in Proteine umgewandelt wird.
Und dies wurde in der Impfstoff-RNA erreicht, indem viele Zeichen durch Gs und Cs ersetzt wurden, wo immer dies möglich war.
Ich bin etwas fasziniert von der einen Änderung, die nicht zu einem zusätzlichen C oder G geführt hat, der CCA -> CCU-Modifikation. Wenn jemand den Grund kennt, lass es mich wissen!
Das eigentliche Spike-Protein
Die nächsten 3777 Zeichen der Impfstoff-RNA sind ähnlich “codonoptimiert”, um viele Cs und Gs hinzuzufügen. Aus Platzgründen werde ich hier nicht den gesamten Code auflisten, aber wir werden ein außergewöhnlich spezielles Bit vergrößern. Dies ist der Teil, der es zum Funktionieren bringt, der Teil, der uns tatsächlich hilft, wieder normal zu leben:
* * L D K V E A E V Q I D R L I T G Virus: CUU GAC AAA GUU GAG GCU GAA GUG CAA AUU GAU AGG UUG AUC ACA GGC Vaccine: CUG GAC CCU CCU GAG GCC GAG GUG CAG AUC GAC AGA CUG AUC ACA GGC L D P P E A E V Q I D R L I T G ! !!! !! ! ! ! ! ! ! !Hier sehen wir auch die üblichen RNA-Veränderungen. Zum Beispiel sehen wir im ersten Codon, dass CUU in CUG geändert wird. Dies fügt dem Impfstoff ein weiteres „G“ hinzu, von dem wir wissen, dass es zur Steigerung der Proteinproduktion beiträgt. Sowohl CUU als auch CUG kodieren für die Aminosäure “L” oder Leucin, sodass sich im Protein nichts geändert hat.
Wenn wir das gesamte Spike-Protein im Impfstoff vergleichen, sind alle Änderungen gleichbedeutend mit Ausnahme von zwei, und das sehen wir hier.
Das dritte und vierte Codon oben repräsentieren tatsächliche Änderungen. Die dortigen K- und V-Aminosäuren werden beide durch “P” oder Prolin ersetzt. Für “K” waren drei Änderungen erforderlich (“!!!”) und für “V” waren nur zwei erforderlich (“!!”).
Es stellt sich heraus, dass diese beiden Änderungen die Impfstoffeffizienz enorm verbessern.
Was passiert hier? Wenn Sie sich ein echtes SARS-CoV-2-Partikel ansehen, können Sie das Spike-Protein auch als eine Reihe von Spikes sehen:
Die Spikes sind am Viruskörper angebracht („das Nucleocapsid-Protein“). Aber die Sache ist, dass unser Impfstoff nur die Spikes selbst erzeugt und wir sie nicht auf irgendeine Art von Viruskörper montieren.
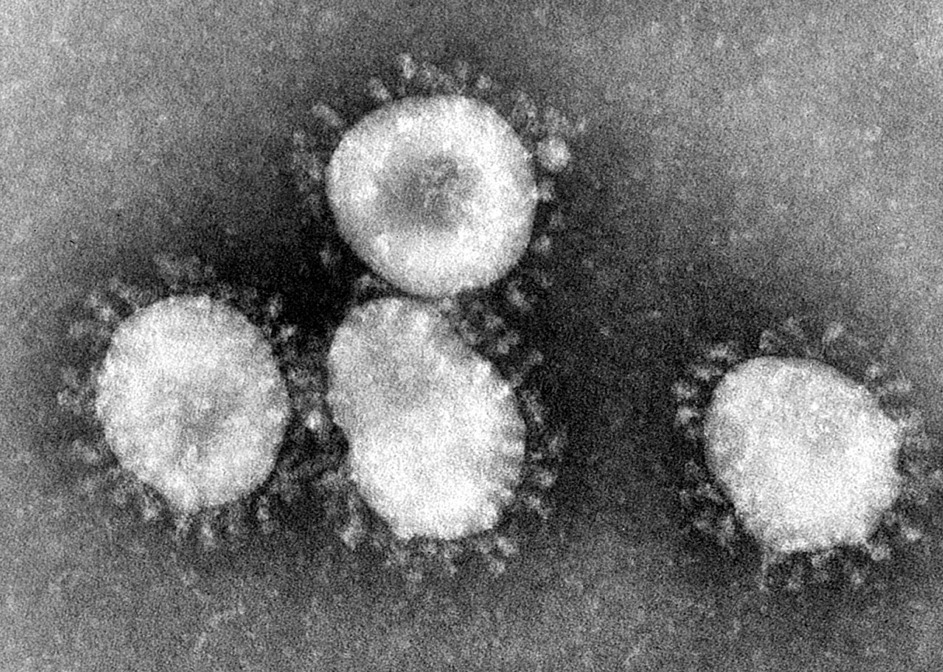
Es stellt sich heraus, dass unmodifizierte, freistehende Spike-Proteine in eine andere Struktur kollabieren. Wenn es als Impfstoff injiziert wird, würde dies in der Tat dazu führen, dass unser Körper Immunität entwickelt. Aber nur gegen das kollabierte Spike-Protein.
Und der echte SARS-CoV-2 zeigt sich mit dem stacheligen Spike. Der Impfstoff würde in diesem Fall nicht sehr gut funktionieren.
Was tun? Im Jahr 2017 wurde beschrieben, wie eine doppelte Prolin-Substitution an genau der richtigen Stelle dazu führen würde, dass die SARS-CoV-1- und MERS S-Proteine ihre Konfiguration vor der Fusion annehmen, auch ohne Teil des gesamten Virus zu sein. Dies funktioniert, weil Prolin eine sehr starre Aminosäure ist. Es wirkt wie eine Art Schiene und stabilisiert das Protein in dem Zustand, den wir dem Immunsystem zeigen müssen.
Die Leute, die dies entdeckten, sollten unablässig herumlaufen und sich selbst gratulieren. Unerträgliche Mengen von Selbstgefälligkeit könnten Sie äussern. Und es wäre sehr verdient.
(In Wirklichkeit sind viele dieser Wissenschaftler äußerst bescheiden – ich würde einfach nicht wissen, was ich mit mir anfangen sollte, wenn ich eine so wichtige Entdeckung gemacht hätte!)
Am Ende eines Proteins finden wir ein “Stop” -Codon, das hier durch Kleinbuchstaben gekennzeichnet ist. Dies ist eine höfliche Art zu sagen, dass das Protein hier enden sollte. Das ursprüngliche Virus verwendet das UAA-Stoppcodon, der Impfstoff verwendet zwei UGA-Stoppcodons, vielleicht nur für ein gutes Maß.
Die 3″ Untranslated Region
Ähnlich wie das Ribosom am 5″-Ende einen Einlauf benötigte, fanden wir am Ende eines Proteins ein ähnliches Konstrukt namens 3″-UTR, wenn wir die “fünf nicht translatierte Hauptregion” fanden.
Über die 3″-UTR könnten viele Worte geschrieben werden, aber hier zitiere ich, was Wikipedia sagt: „Die 3′-untranslated Region spielt eine entscheidende Rolle bei der Genexpression, indem sie die Lokalisierung, Stabilität, den Export und die Translationseffizienz einer mRNA beeinflusst. Trotz unseres derzeitigen Verständnisses von 3″-UTRs sind sie immer noch relative Geheimnisse. “
Was wir wissen ist, dass bestimmte 3″-UTRs die Proteinexpression sehr erfolgreich fördern. Gemäß dem WHO-Dokument wurde der BioNTech / Pfizer-Impfstoff 3″-UTR aus “dem aminoterminalen Enhancer der Split (AES) -mRNA und der mitochondrial codierten 12S-ribosomalen RNA ausgewählt, um RNA-Stabilität und hohe Gesamtproteinexpression zu verleihen”. Zu dem sage ich, gut gemacht.
Das AAAAAAAAAAAAAAAAAAAAAAAA Ende von allem
Das Ende der mRNA ist polyadenyliert.
Dies ist eine ausgefallene Art zu sagen, dass sie mit einer Menge von vielen AAAAAAAAAAAAAAAAAAA endet.
Sogar mRNA hat genug von 2020, wie es scheint.
mRNA kann viele Male wiederverwendet werden, aber wenn dies passiert, verliert sie am Ende auch einige der A-Werte. Sobald das A aufgebraucht ist, ist die mRNA nicht mehr funktionsfähig und wird verworfen.
Auf diese Weise schützt der „Poly-A“ -Schwanz vor Verschlechterung.
Es wurden Studien durchgeführt, um herauszufinden, wie hoch die optimale Anzahl von A am Ende für mRNA-Impfstoffe ist. Ich habe in der offenen Literatur gelesen, dass dies bei 120 oder so seinen Höhepunkt erreichte.
Der BNT162b2-Impfstoff endet mit:
****** **** UAGCAAAAAA AAAAAAAAAA AAAAAAAAAA AAAAGCAUAU GACUAAAAAA AAAAAAAAAA AAAAAAAAAA AAAAAAAAAA AAAAAAAAAA AAAAAAAAAA AAAAAAAAAA AAAADies sind 30 A, dann ein “10 Nucleotid Linker” (GCAUAUGACU), gefolgt von weiteren 70 A.
Ich vermute, dass das, was wir hier sehen, ist das Ergebnis einer weiteren proprietären Optimierung, um die Proteinexpression noch weiter zu verbessern.
Zusammenfassung
Damit kennen wir jetzt den genauen mRNA-Gehalt des BNT162b2-Impfstoffs und verstehen größtenteils, warum sie dort sind:
Die CAP, um sicherzustellen, dass die RNA wie normale mRNA aussieht.
Eine bekannte erfolgreiche und optimierte 5′-untranslatierte Region (UTR).
Ein codonoptimiertes Signalpeptid, um das Spike-Protein an die richtige Stelle zu schicken (100% vom ursprünglichen Virus kopiert).
Eine codonoptimierte Version des ursprünglichen Spikes mit zwei Prolin-Substitutionen, um sicherzustellen, dass das Protein in der richtigen Form erscheint.
Eine bekannte erfolgreiche und optimierte 3′-Region ohne Übersetzung.
Ein etwas mysteriöser Poly-A-Schwanz mit einem ungeklärten „Linker“.
Die Codonoptimierung fügt der mRNA viel G und C hinzu.
Währenddessen hilft die Verwendung von Ψ (1-Methyl-3′-pseudouridylyl) anstelle von U dabei, unser Immunsystem zu umgehen, sodass die mRNA lange genug in der Nähe bleibt, damit wir das Immunsystem tatsächlich trainieren können.
Eine klare Darstellung!
Erstaunlich, was Biologie, Technik und Informatik zusammen leisten können!
Leck mich am Penning!!Das ist der Bioinformatik-Porno des Jahres. Hut ab so gut und durchdacht. Besser geht es nicht!!
Die Blumen bitte an:
https://twitter.com/PowerDNS_Bert